
UnicodeとUTF-8の違い。UTF-8・UTF-16・UTF-32とは
インターネットが世界中で普及している現代では、世界中のコンピュータが相互にデータを授受できるように、文字コードの統一が必須です。
そこで,考案されたのがUnicode(ユニコード)と呼ばれるコード体系です。
UnicodeはISO(国際標準化機構)規格となり、国際的に認められています。
文字コードに関する記事はこちら

この記事では
- Unicode
- UTF-8・UTF-16・UTF-32の違い
それぞれ説明していきます。
Unicode

Unicodeとは、世界中の文字を扱えるようにしたISO(国際標準化機構)規格の文字集合の事を指します。
文字集合とは、
- コンピュータが認識出来る文字の範囲の事
- 文字コードを区別する2段階の一つ
です。
文字コードは
- 符号化文字集合(character set)
- 符号化方式(character encording scheme)
と2段階に区別する事が出来ます。
Unicode以外の文字集合には
- JIS・・・平仮名・カタカナ・漢字、ラテン基本文字、記号 等々
- KS・・・ハングル文字、ラテン基本文字、記号 等々
があります。
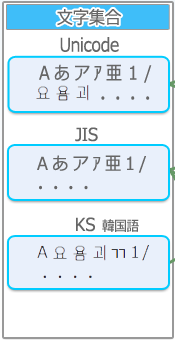
文字集合では、それぞれの文字に対応したビット値があります。
文字集合の文字に対応したビット値は、符号位置(コードポイント)と呼ばれています。
符号位置(コードポイント)は、
- 文字集合を構成する文字を並べて順番に振った数値
- あくまで、その文字の文字集合内での位置
であり、符号化方式とは別物です。
Unicodeの符号位置(コードポイント)の一例です。
| 文字 | コードポイント |
|---|---|
| 1 | U+0031 |
| A | U+0041 |
| あ | U+3042 |
| 丈 | U+4E08 |
同じ文字でも文字集合が違えば、符号位置(コードポイント)も違います。
| Unicode | JIS X 0208 | |
|---|---|---|
| 「1」の符号位置(コードポイント) | U+0031 | 3区1点16 |
| 「A」の符号位置(コードポイント) | U+0041 | 3区1点32 |
| 「あ」の符号位置(コードポイント) | U+3042 | 4区2点0 |
Unicodeの符号位置(コードポイント)は、
- 面・・・8 bitのデータ幅
- 区・・・8 bitのデータ幅
- 点・・・8 bitのデータ幅
合計24bitのデータ幅を利用しています。
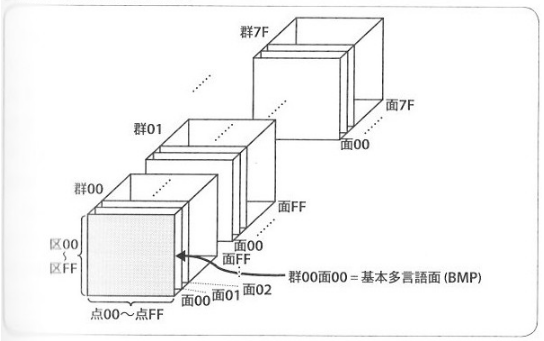
| 面 | コード位置 | 名称、用途 |
|---|---|---|
| 第0面 | U+0000~U+FFFF | ・基本多言語面(Basic Multilingual Plane:BMP) ・現在よく使われている欧米のアルファベットやCJK漢字コードなどが割り当てられている。最初のUnicode規格で制定されていた領域 ・この面のコードは16bit以内で表現できるため、コード効率がよい |
| 第1面 | U+10000~U+1FFFF | ・追加多言語面(Supplementary Multilingual Plane:SMP) ・現在ではあまり使われていない古代の文字や、顔文字などの記号類を収容 |
| 第2面 | U+20000~U+2FFFF | ・追加漢字面(Supplementary Ideographic Plane:SIP) ・人名でしか使わないような、使用頻度の低い漢字などを収容 |
| 第3面 | U+30000~U+3FFFF | ・第三漢字面(Tertiary Ideographic Plane:TIP) ・甲骨文字などの古代文字を収容する予定の領域 |
| 第4~13面 | U+40000~U+ DFFFF | (未使用) |
| 第14面 | U+E0000~U+EFFFF | ・追加特殊用途面(Supplementary Special‐purpose Plane:SSP) ・言語タグや異体字セレクタなどを収容 |
| 第15面 | U+F0000~U+FFFFF | ・私用面(Private Use) ・外字などで使用できる |
| 第16面 | U+100000~U+10FFFF | ・私用面(Private Use) ・外字などで使用できる |
| 基本多言語面(BMP)の構成 | |
|---|---|
| 0 〜 33 | ・ラテン、ギリシャ、キリル、ヘブライ、アラビア等 ・インド系文字群等 ・記号類 ・平仮名・片仮名等 |
| 34 〜 4D | CJK統合漢字拡張A |
| 4E 〜 9F | CJK統合漢字 |
| A0 〜 A4 | イ文字 |
| A5 〜 AB | |
| AC 〜 D7 | ハングル |
| D8 〜 DF | サロンゲート領域 |
| E0 〜 F8 | 私用領域 |
| F9 〜 FA | CJK互換漢字 |
| FB 〜 FE | アラビア文字表現形等 |
| FE 〜 FF | 全角・半角形 |
UTF-8・UTF-16・UTF-32の違い

- UTF-8
- UTF-16
- UTF-32
とは、文字集合であるUnicodeから符号化(エンコーディング:Encoding)する符号化方式の種類です。
符号化方式(Character Encoding Scheme、CES)とは、文字集合の符号位置(コードポイント)を、実際にコンピュータが利用できるデータ列(通常、バイト列)に変換し符号化(エンコーディング:Encoding)する方式の事を指します。
Unicodeの符号位置(コードポイント)「U+0000~U+10FFFF」(16進数表記)から
- 8 bit単位
- 16 bit単位
- 32 bit単位
で符号化した符号化方式が
- UTF-8
- UTF-16
- UTF-32
になります。
| 文字 | コードポイント | UTF-8 | UTF-16 | UTF-32 |
|---|---|---|---|---|
| 1 | U+0031 | 31 | 00 31 | 00 00 00 31 |
| A | U+0041 | 41 | 00 41 | 00 00 00 41 |
| あ | U+3042 | e3 81 82 | 30 42 | 00 00 30 42 |
| 丈 | U+4E08 | e4 b8 88 | 4e 08 | 00 00 4e 08 |
例えば、UnicodeをUTF-8で符号化(エンコーディング:Encoding)する場合、
- 符号化文字集合内の符号位置(コードポイント)【U+3042】を
- UTF-8という符号化方式で符号化(エンコーディング:Encoding)して
- 【0xE38182】というバイト列に変換
コンピュータが利用できるデータ列に変換します。
| 文字集合 | 「あ」の符号位置(コードポイント) | 符号化方式 | バイト列 |
|---|---|---|---|
| Unicode | U+3042 | UTF-8 → → → → → (エンコード:符号化) | 0xE38182 |
| UTF-8 ← ← ← ← ← (デコード:復号化) |
符号化文字集合と符号化方式の関係は以下の図のようになっています。

UTF-8
UTF-8(Unicode Encoding Forms 8)は、符号位置(コードポイント)の値によって長さが1 ~ 4bytesに変化する可変長の符号化方式です。
UTF-8の特徴は
- 最も頻繁に使われる(U+0000 ~ U+007F)の文字(ASCII文字/半角英数字)は1byteに収まり、コード効率が高い
- ラテン圏でよく使われる文字範囲(U+0080 ~ U+07FF)は2bytesで済み、コード効率が良い
- 基本的な漢字はほぼ基本多言語面(BMP)(U+0000 ~ U+FFFF)に収容されており、ほとんどの日本語文字は3bytes
例えば、16bitの符号位置(コードポイント)は、
- 4bit
- 6bit
- 6bit
の3つに分解し、3bytesのデータに変換されます。
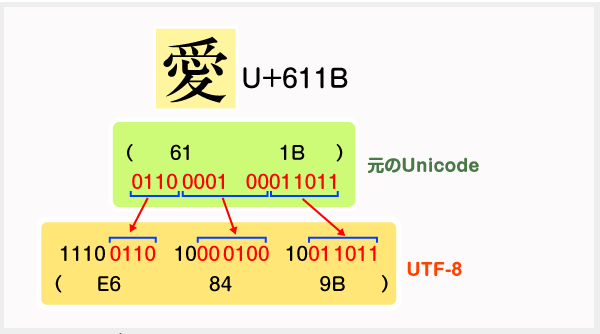
UTF-16
UTF-8は
- ファイルへの保存や通信等では便利
- メモリの利用効率も高い
ですが、1byte単位の可変長データなのでプログラムから操作するには不便です。
そこで、固定長データとして符号化する
- UTF-16
- UTF-32
の符号化方式が用意されました。
UTF-16は
- Unicodeの符号位置(コードポイント)を16bitで表現する方式
- U+0000 ~ U+FFFFの範囲ならそのまま16bitデータとして格納
- U+10000 ~ U+10FFFFの符号位置(コードポイント)はサロゲートペアを使って表現
という特徴を持つ符号化方式です。
サロゲートペア
サロゲートペア(surrogate pair:代用対)とは、Unicodeに第1面(SMP)以降を追加したときに導入された新しい符号化方法です。
16bit幅の符号位置(コードポイント)を2つ使い、U+10000 ~ の文字を表現します。
当初のUnicodeは、
- 符号位置符号位置(コードポイント)を全て16bitで表現
- 1文字当たり16bit幅の変数が1つあればUnicodeの符号位置(コードポイント)を収容
していましたが、U+10000 ~ の符号位置(コードポイント)ではこれは不可能です。
そこで、16bit × 2 ペアで全ての符号位置(コードポイント)を扱う方法(サロゲートペア)が考案されました。
基本多言語面(BMP)の未使用領域にあった符号位置(コードポイント)の内、
- U+D800 ~ U+DBFF(1024文字分)
- U+DC00 ~ U+DFFF(1024文字分)
これらのペアを使って、1024 × 1024 = 約100万文字分のコード領域を確保し、これを U+10000 ~ U+10FFFFに割り当てました。
サロゲートペアへの変換は、
- 符号位置(コードポイント)からU+10000を減算
- 20bitの数値に変換
- それを上下10bitずつに分割
- それぞれの値に
- U+D800
- U+DC00
を加算
という手順を踏みます。

UTF-32
UTF-32は、サロゲートペアを使わずに、常に32bitでUnicodeの符号位置(コードポイント)を表現する符号化方式です。
基本多言語面(BMP)以外のUnicodeの符号位置(コードポイント)が使われることは非常に少ないため、実際にはほとんどの場合は上位 16bitがゼロになり、メモリの利用効率はあまり良くありません。
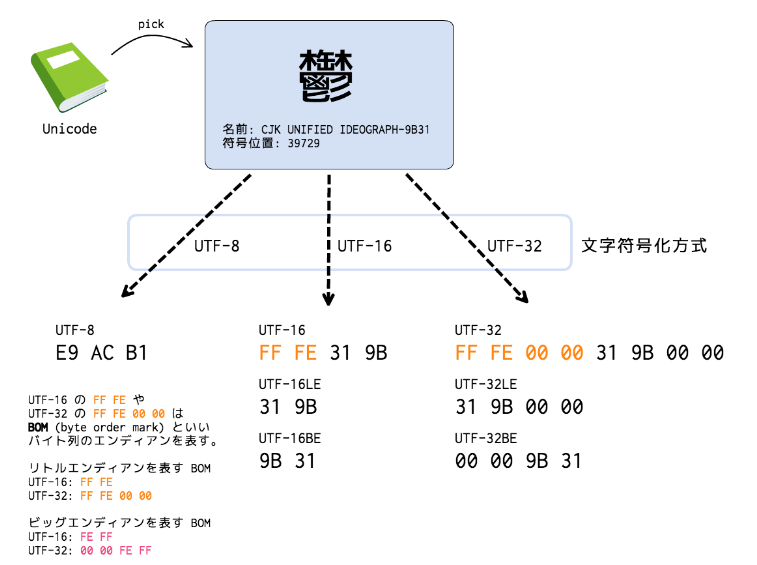
エンディアン
UTF-16やUTF-32では、2bytes(16bit)もしくは4bytes(32bit)で1つの文字コードを表現しています。
このようなデータをメモリ上に格納したり、ファイルに保存したりする場合は、その「バイトオーダー(エンディアン)」属性について考慮する必要があります。
- バイトオーダー(Byte Order)・・・バイトを並べる順番
- エンディアン(Endian)・・・多バイト(2bytes以上)のバイト幅を持つ整数データをメモリーに格納する際の、記録・転送方法
は同義語になります。
Unicodeで符号化されていることおよび符号化の種類の判別の為に、BOM(Byte Order Mark)が使用されます。
BOMは、Unicodeの符号化形式で符号化したテキストの先頭につける数バイトのデータのです。。
- ビッグエンディアン(BE)・・・データの最上位バイトから順に格納する方式
- リトルエンディアン(LE)・・・データの最下位バイトから順に格納する方式
| BOM(Byte Order Mark) | リトルエンディアン(LE) | ビッグエンディアン(BE) |
|---|---|---|
| UTF-16のFF FE | FF FE | FE FF |
| UTF-32のFF FE 00 00 | FF FE 00 00 | 00 00 FE FF |
「U+29E49」というUnicodeの符号位置(コードポイント)を、
- UTF-32 ビッグエンディアン(BE)でメモリに格納すると「00 02 9E 49」という順
- UTF-32 リトルエンディアン(LE)だと「49 9E 02 00」という順
になります。
UTF-8・UTF-16・UTF-32
- UTF-8
- UTF-16
- UTF-32
の違いは、Unicodeという符号化文字集合の中の符号位置(コードポイント)からビット列からコンピュータが認識出来るバイト列へ変換する符号化方式にあります。
以上が、
- Unicode
- UTF-8・UTF-16・UTF-32の違い
それぞれの説明になります。


コメント
[…] 参考 UnicodeとUTF-8・UTF-16・UTF-32の違いとはYone's archive SHARE […]