
文字コードとは?コンピュータの文字コードの種類
私たち人間は、
- 数字(10進数:0 〜 9)
- 文字
- 平仮名(あ 〜 ん)
- 片仮名(ア 〜 ン)
- 漢字
- アルファベット(A ~ Z)
- 音
- 色 等々
を認識出来ますが、コンピュータは
- 数字(10進数)
- 文字
- 音
- 色 等々
の違いは認識出来ません。
コンピュータが認識出来るのは、コンピュータを構成しているIC(Integrated Circuit:集積回路)の1本1本のピンに電気が
- 流れているか
- 流れていないか
だけです。
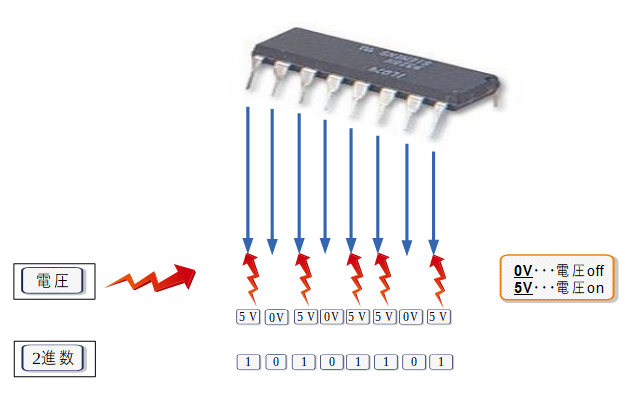
では、どのようにしてコンピュータは電気信号だけで
- 文字
- 音
- 色 等々
を認識して、出力装置であるディスプレイに表示しているのでしょうか。
この記事では、
- コンピュータがどのように電気信号を扱い、文字・音・色を認識しているか
- 文字コード
- 文字コードの種類
についてそれぞれ説明していきます。
コンピュータがどのように電気信号を扱っているのか

コンピュータが直接、認識出来るのは
- 0(電気が流れていない)
- 1(電気が流れている)
の2進法(進数)しかありません。
2進法(進数)についての記事はこちら

ところが、コンピュータを使う人間は数値以外のデータである
- 文字
- 音
- 色 等々
もコンピュータで認識して欲しいため、2進数を利用して
- 文字
- 音
- 色 等々
を2進数の数値で表す符号化(コード化)します。
符号化(コード化)とは、データである
- 数字(10進数)
- 文字
- 音
- 色 等々
を数値化することです。
具体的には、文字の場合
- A・・・100 0001
- あ・・・0010 0100 0010 0010
- 愛・・・0011 0000 0010 0110
色の場合
- 白色・・・1111 1111 1111 1111 1111 1111(#FFFFFF:16進数)
- 黒色・・・0000 0000 0000 0000 0000 0000(#000000:16進数)
上記の様に、各データに対して2進数(または16進数)の値で置き換える事です。
データに任意の数字を付ければいいので、データに対する2進数(または16進数)の値の付けた方は無数にあります。
16進数についての記事はこちら

符号化(コード化)には、
- コンピュータを使う人間が自由に行う場合
- 予め決められた符号化のルールに従わなければならない場合
の2通りあります。
- 文字
- 色
等々のデータをコンピュータで扱うには、あらかじめ定められた符号化(コード化)のルールに従わなければなりません。
- キーボード
- プリンタ
- ディスプレイ
などの出入力装置は、特定のルールで符号化(コード化)された
- 文字(文字コード)
- 色(色コード)
を取り扱います。
独自に定めた
- 文字(文字コード)
- 色(色コード)
の符号化(コード化)では出入力装置は正しく動作しません。
文字コード

コンピュータの世界では統一的な文字コードが定められています。
文字コードの符号化(コード化)は1種類だけではありません。
皆さんの中で、コンピュータ(パソコン)を利用する際に、「文字化け」を経験したことはありませんか。
これは、文字コードが複数あるのが原因です。
この文字コードは
- 符号化文字集合(character set)
- 符号化方式(character encording scheme)
と2段階に区別する事が出来ます。
符号化文字集合
符号化文字集合 (coded character set)とは
- 文字集合を定める
- その文字集合内の文字に対応したビット値を決める
規則的な集合の事を指します。
文字集合とは、コンピュータが認識出来る文字の範囲の事です。
- Unicode・・・世界中の文字、記号 等々
- JIS・・・平仮名・カタカナ・漢字、ラテン基本文字、記号 等々
- KS・・・ハングル文字、ラテン基本文字、記号 等々
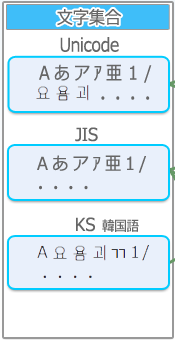
- JIS X 0201・・・ラテン基本文字と片仮名の文字範囲
- JIS X 0208・・・日本語(平仮名・カタカナ・漢字)の2バイト文字の文字範囲
の文字集合があります。
文字集合でコンピュータが認識出来る文字の範囲を定めた後、文字集合の文字に対応したビット値を決める必要があります。
文字集合の文字に対応したビット値を、符号位置(コードポイント)と呼びます。
符号位置(コードポイント)
符号位置(コードポイント)とは、文字集合内の文字をビット値で表した値の事を指します。
符号位置(コードポイント)は、
- 文字集合を構成する文字を並べて順番に振った数値
- あくまで、その文字の文字集合内での位置
であり、後に説明する符号化方式とは別物です。
文字集合で有名なUnicodeの符号位置(コードポイント)の一例です。
| 文字 | コードポイント |
|---|---|
| 1 | U+0031 |
| A | U+0041 |
| あ | U+3042 |
| 丈 | U+4E08 |
同じ文字でも文字集合が違えば、符号位置(コードポイント)も違います。
| Unicode | JIS X 0208 | |
|---|---|---|
| 「1」の符号位置(コードポイント) | U+0031 | 3区1点16 |
| 「A」の符号位置(コードポイント) | U+0041 | 3区1点32 |
| 「あ」の符号位置(コードポイント) | U+3042 | 4区2点0 |
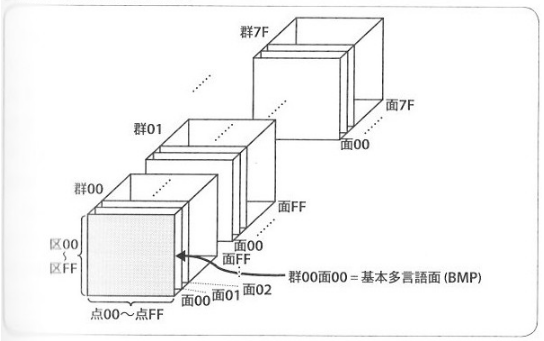
符号位置(コードポイント)は符号空間(座標みたいなもの)内で、一つ一つの文字が割り振られています。
符号空間は
- 群・・・多数の面からなる部分集合
- 面・・・多数の区からなる面状の部分集合
- 区・・・多数の点からなる線状の部分集合
- 点・・・符号位置(コードポイント)の位置
で構成されています。
下記の挿入図はUnicodeの符号位置(コードポイント)です。
基本多言語面(Basic Multilingual Plane, BMP)とは、Unicodeの第0面になります。
符号化方式
符号化方式(Character Encoding Scheme、CES)とは、文字集合の文字と対応したビット値を、実際にコンピュータが利用できるデータ列(通常、バイト列)に変換し符号化(エンコーディング:Encoding)する方式の事を指します。
例1)JIS X 0208の場合
- 符号化文字集合内の符号位置符号位置(コードポイント)【4区2点】を
- Shift_JISという符号化方式で符号化(エンコーディング:Encoding)して
- 【0x82A0】というバイト列に変換する
例2)Unicodeの場合
- 符号化文字集合内の符号位置(コードポイント)【U+3042】を
- UTF-8という符号化方式で符号化(エンコーディング:Encoding)して
- 【0xE38182】というバイト列に変換する
Shift_JIS・UTF-8を使ってこのように符号化(エンコーディング:Encoding)し、コンピュータが利用できるデータ列に変換します。
| 文字集合 | 「あ」の符号位置(コードポイント) | 符号化方式 | バイト列 |
|---|---|---|---|
| Unicode | U+3042 | UTF-8 → → → → → (エンコード:符号化) | 0xE38182 |
| UTF-8 ← ← ← ← ← (デコード:復号化) |
|||
| JIS X 0208 | 4区2点0 | Shift_JIS → → → → → (エンコード:符号化) | 0x82A0 |
| Shift_JIS ← ← ← ← ← (デコード:復号化) |
符号化文字集合と符号化方式の関係は以下の図のようになっています。

符号化方式には
- Shift_JIS
- EUC-JP(Unix系OS)
- ISO-2022-JP
- UTF-8
- UTF-16 等々
多種存在します。
文字コードの種類

コンピュータが多くの言語圏で利用されるにつれて文字コードの種類も増大し、現在では100種類以上の代表的な文字コードが存在します。
ここでは、文字コードで有名な
- ASCII
- JIS
- Unicode
の概要を説明します。
ASCII
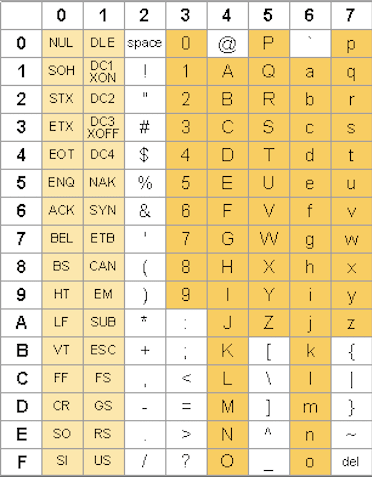
文字コードの元祖です。
- ASCII(american standard code for information interchange)の略
- ANSI(米国規格協会)が制定
- 英数記号を1文字7ビットで表します
-
- アルファベット
- 数字
- 記号 等
94個の図形文字と34個の機能キャラクタの計128文字で構成
コンピュータが取り扱うデータの基本単位は1バイト = 8ビットですが、7ビットあれば128通り(2 ^ 7)の文字を表せるので、英数記号を表示するには十分な量です。
1ビットでもデータを短くする事で、少しでも通信時間を短縮したいという工夫がされています。
ASCIIを文字コードとして選択すると、
- 0・・・011 0000
- 9・・・011 1001
- A・・・100 0001
- Z・・・101 1010
- b・・・110 0010
- %・・・010 0101
上記の様に7ビットの2進数に符号化(コード)されています。
ASCIIでは日本語は扱えません。
JIS(日本工業規格)
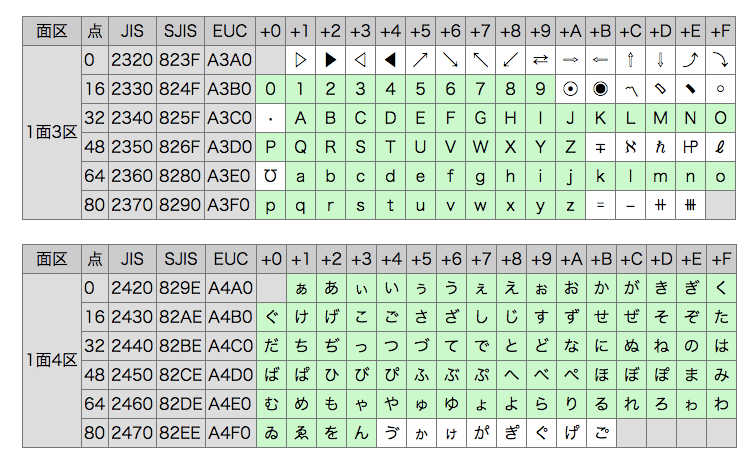
JIS(日本工業規格)は、日本語用の文字コードです。
符号化文字集合には
- JIS X 0201
- JIS X 0208
- JIS X 0212
- JIS X 0213 等々
があります。
| 制定 | 規格 | 文字集合 | |
|---|---|---|---|
| JIS X 0201 | 1969年 | 7ビット符号と8ビット符号での運用 | ・ラテン文字用図形文字集合 ・片仮名用図形文字集合 |
| JIS X 0208 | 1978年 | 7ビット及び8ビットの2バイト情報交換用符号化漢字集合 | 日本語表記、地名、人名などで用いられる6,879図形文字 |
| JIS X 0212 | 1990年 | 情報交換用漢字符号-補助漢字 | JIS X 0208:1983に含まれない文字を集めた、6067字の符号化文字集合 |
| JIS X 0213 | 2000年 | 7ビット及び8ビットの2バイト情報交換用符号化拡張漢字集合 | JIS X 0208:1997を拡張した日本語用の符号化文字集合 |
文字符号化方式では、
- ISO-2022-JP
- EUC-JP
- Shift_JIS
が有名です。
| ISO-2022-JP | International Organization for Standardization | インターネット上(特に電子メール)などで使われる日本の文字用 |
| EUC-JP | Extended UNIX Code Packed Format | UNIX上で日本語の文字を扱う場合に利用されてきた文字コードの一つ |
| Shift_JIS | コンピュータ上で日本語を含む文字列を表現するために用いられる文字コードの一つ |
Unicode
インターネットが普及し、世界中のコンピュータが相互にデータを授受できるようにするためには、文字コードの統一が必要です。
そこで,考案されたのがUnicode(ユニコード)と呼ばれるコード体系です。
Uniとは「Uniform = 統一」という意味です。
UnicodeはISO(国際標準化機構)規格となり、国際的に認められています。
Unicodeに関する記事はこちら

以上、
- コンピュータがどのように電気信号を扱い、文字・音・色を認識しているか
- 文字コードの
- 符号化文字集合
- 符号化方式
- 文字コードの種類
についての説明になります。


コメント